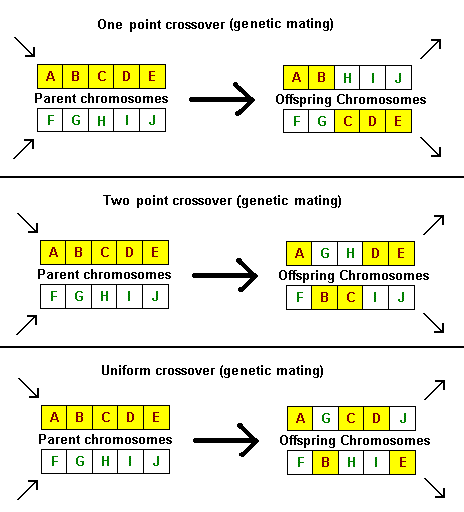
Evolving A Better Solution Biological EvolutionIn the natural world, an organism's "fitness" can be measured by its ability to successfully reproduce. A fit organism must survive long enough in its environment, by finding food and avoiding being killed by another organism, so it can find a mate and reproduce. Sexual reproduction ensures that its genes will survive in the species' gene pool for at least one more generation. Over time, this process of natural selection increases the number of "fit" genes in the gene pool while "unfit" genes become scarce. Simulating Evolution on the ComputerEvolutionary computing techniques, such as genetic algorithms (GAs), attempt to simulate this biological process on the computer in order to solve difficult problems. Pioneered by John Holland [1] in the 1970s, GAs have yet to create a better eye or a bat that can sing. But programmers have employed them for such diverse tasks as optimizing networks, calculating neural network weights, maximizing mathematical functions, scheduling resources more efficiently, minimizing costs in architectural designs while still meeting design constraints, and designing proteins in the pursuit of new drugs.
You generally let this process go on for a predetermined number of generations or until the standard deviation among the fitness levels converges toward zero (when the standard deviation converges, the chromosomes are generally not getting any fitter, so you've arrived at the best solution you are going to find). Assuming that your initial population was large enough and your fitness function well defined, you will have arrived at a good solution. Note that I say "good solution". GAs do not always find the best or ideal solution. But if you run your simulated evolution many times, you will tend to find a very good solution, if not the perfect one (by the way, my GA library has an option to do multiple runs for you automatically). My Java GA Class LibrarySo how did I model this evolutionary process in Java? I created an abstract chromosome class (called Chromosome) which stores the genes and an abstract genetic algorithm class (called GA) that contains chromosome objects as instance variables and implements the basic methods for doing genetic mating with crossover, mutations, and iterating through the simulated evolution. Thus, I was able to implement most of my code in this GA ancestor class whose methods operate on abstract chromosomes. I also declared a few chromosome "type" specific methods (such as doOnePtCrossover() and doRandomMutation()) as abstract, so that they could be implemented in the appropriate subclasses. public class MyGA extends GAFloat {
public MyGA() { //calls super() with params }
double getFitness(int iChromIndex) { ... }
public static void main(String[] args) { ... }
} In your constructor, you will need to pass several parameters to super(). Among these parameters are the size of your chromosomes (how many genes they have), the population size, the crossover probability (the fraction of reproducing chromosomes undergoing crossover), the number of generations to evolve, the number of preliminary runs/generations (to build good breeding stock for the main evolution run), the mutation probability, the decimal point precision (for genes stored as floating-point numbers), the gene space (possible gene values), and the crossover type. The example GA source code will give you ideas on what values to assign to each of these parameters. A Simple Binary Number ExampleLet's start with a simple example: writing a GA to determine the largest binary number possible. In this case, we could extend the GAString class that will store our binary numbers as strings (such as "0101101011"). If we specify a chromosome dimension of 10 in our constructor, we're hoping the GA will figure out that the largest binary number (chromosome) is "1111111111". protected double getFitness(int iChromIndex) {
String s; s = chromosomes[iChromIndex].getGenesAsStr(); return(getChromValAsDouble(s)); } Defined in the GAString class, the getChromValAsDouble() method automatically detects and converts binary chromosomes, integer chromosomes, or floating-point chromosomes to their corresponding double value. Finally, we can write a main() method to instantiate our GA. Since the abstract GA class implements the Runnable interface, we can execute our GA within the context of a thread. public static void main(String[] args) {
GABinaryOnes binGA = new GABinaryOnes(); Thread threadBinaryOnes = new Thread(binGA); threadBinaryOnes.start(); } The thread's start() method ultimately invokes GA.evolve(), the main routine that runs evolution according to parameters previously passed into the constructor. Using two-point crossover, a chromosome size of 20, and a mutation probability of 1 percent, my GABinaryOnes example took less than 1 second to arrive at the fittest chromosome of "11111111111111111111". To retrieve this value, just call the GA.getFittestChromosome() method.
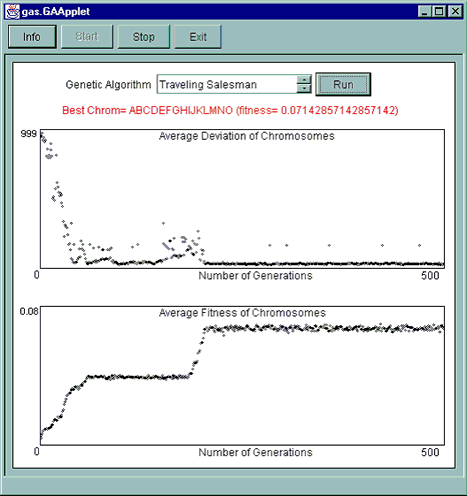
A More Complicated (Traveling Salesman) ExampleA more complicated and interesting example is to use genetic algorithms (GAs) to solve the "traveling salesman" problem [4]. In this classic problem, a salesman is traveling to N cities, all in one trip, and wants to take the shortest route that brings him to all N cities without visiting any twice. This problem is actually very similar to a problem faced on the Internet everyday: How should a packet of information be routed through the Internet (a network of N nodes) so that it gets from point A to point B while going through the fewest nodes possible? It turns out that the search space (the number of possible solutions) of the traveling salesman problem increases as the factorial of the number of cities. So if our salesman needed us to optimize his route for a 20-city tour, there are 2.4 x 10¹8; possible routes he can take. If we had a supercomputer evaluate all possible solutions at a rate of 1,000 possible routes per second, it would take 7,710 years to arrive at the optimal route! And adding just one more city to his itinerary would increase by the possible solutions by a factor of 21! Obviously, this problem cannot be solved by a brute force evaluation of all possible solutions. We can solve this problem, however, by extending the GASequenceList class, which stores chromosomes in the form of character strings. We can code these solutions in the form of chromosome strings such as "ABCDEFGHIJ" and "ACBDEGFHJI", where each letter represents a city. The GASequenceList class automatically prevents duplicate genes from appearing in our chromosomes. This is important for our salesman problem, because we don't want the GA to determine that the best chromosome is "AAAAAAAAAA" (basically, minimize the distance traveled by staying in city A for the duration of the trip!). In our constructor, we pass in a parameter designating our "gene space" or list of possible gene values as the letters we've coded for each city. So if we have the cities A-J, we specify "ABCDEFGHIJ" for that parameter. GASequenceList will enforce the constraint that all chromosomes have some permutation of those 10 characters with no duplicates. So "CBADEFGHIJ" would be a legitimate chromosome, but "CCADEFGHIJ" would not since it duplicated the gene "C". We will also need to write a getFitness() function that will calculate the distance traveled by our salesman as defined in the route stored in a given chromosome. For example, a chromosome like "ABCDEFGHIJ" might result in a route of 3,200 miles, while a chromosome like "ACBEDFGJIH" might result in 4,000 miles. Each city's coordinates could be stored in one, two, or three dimensions. In my example, I placed each city in a one-dimensional universe (a straight line) to simplify the code, but it's easy enough to extend the getFitness() function to calculate distances in two or three dimensions. And remember, the getFitness() function will need to return a high fitness value when the total distance traveled is small and a lower value when the distance is great. To achieve this, my getFitness() function returns one divided by the distance. Using two-point crossover and performing 50 preliminary runs with a population of 300 chromosomes and a mutation probability of 5 percent, my GASalesman example solves the 20-city problem in 50 seconds (on a Pentium III 700 laptop). A Curve-Fitting Example Using Floating-point NumbersAs a (nearly!) universal problem solver, GAs can also be used to do curve fitting. That is, suppose you have a set of data points collected from some electronic instrument and you want to come up with a polynomial equation that fits (and can plot) the data. Such an equation could be useful for extrapolating values for points not in your measured data set. While other mathematical methods [5] have been specially tailored to do this (e.g., Least Squares), GAs are also surprisingly good at solving this problem. To do curve fitting with my GA library, simply extend the GAFloat class. Each chromosome will then consist of a set of floating point numbers (genes), each of which will represent a coefficient in the polynomial to be discovered. The polynomial being fitted will look something like this (assuming you are looking for a fourth degree polynomial): c4*x4 + c3*x3 + c2*x2 + c1 + c0 = D Where c4, c3, c2, c1, and c0 are the coefficients you are solving for and D is a data point value. You'll need to write a getFitness() function that plugs each gene from a candidate chromosome into these coefficients and then tests the fitness of this "equation" against the set of data points. Highly fit chromosomes (polynomial equations) will generate values that closely match the data points. Over time, the GA will evolve the correct set of coefficients to the equation, giving you a good curve-fitting solution. Using two-point crossover, two decimal points precision, a population of 100 chromosomes, and a mutation probability of 10%, my GACurveFit example finds a second degree polynomial, that fits a set of eight data points, in under 4 seconds. Running Sample Genetic AlgorithmsTo run my sample genetic algorithms, I created a simple applet that lets you choose between binary ones, curve fitting, traveling salesman, and trigonometric functions. It also plots the statistics computed by the algorithm: average deviation and average fitness. By looking at these graphs, you can get an idea of how many generations were run before the GA converged on the solution. The following diagram illustrates the interesting observation that evolution occasionally stagnates at a certain fitness level (a local maxima) for many generations and then dramatically improves in just several generations. Is this a manifestation of Eldredge and Gould's theory of punctuated equilibrium [6], which postulates that long periods of relative evolutionary equilibrium are punctuated by short periods of rapid change? Figure 3. Plots of the Traveling Salesman genetic algorithm.
SummaryWhile there is no guarantee that genetic algorithms will find the optimal or "best" solution to a complex problem, they have been successfully applied to a wide variety of theoretical problems such as optimizing information networks and optimizing obtuse mathematical functions. They are also applied to more "concrete" problems in areas such as engineering. For example, suppose you want to build a bridge that is stable, cheap, and simple to construct. You could use GAs to build thousands of simulated bridges (encoded as chromosomes), test them in a fitness function, and evolve a good bridge design. Or perhaps you are an aeronautical engineer looking to design a superior aircraft wing. GAs could evolve a better wing design for you. Mortgage lenders use GAs to determine the best criteria for determining whether to extend loans. Stockbrokers use them to optimize trading strategies or to look at mountains of data to find subtle stock trends (such as sector A tends to rise when the prime rate is below X and inflation is greater than Y). There are probably many clever uses for GAs that have yet to be discovered. The trick, if one exists, is to write a fitness function that can successfully guide the evolutionary process. A GA will never be able to "evolve" a solution for which there is no fitness function. For example, without the positive feedback of a fitness function, you'd never be able to create a GA that can break an encrypted password or descramble a satellite signal. But if you are clever enough to create a viable fitness function, you can probably find a good solution to your problem by implementing a GA and harnessing the power of simulated evolution.
The Java GALib is now an open source project on SourceForge.net. |